
由中国人工智能学会、杭州市余杭区人民政府主办,杭州后世科技城管委会、京东零售联合承办“2022全球人工智能技术独创大赛—算法挑战赛”于5月21日结束复赛,
本次大赛从人工智能领域技术发展与跨界应用与融合出发,开设电商根本属性图文匹配、商品标题实体识别两個赛道,以打造人工智能人才交流平台、产业生态圈,促进人工智能相关领域独创与发展,
经过激烈复赛,大赛引发两個赛道7-14名获奖队伍,在征求选手意愿后,咱们将分两期对两個赛道一部分选手比赛方案实行共享,本次共享是赛道一选手参赛方案,
赛道一:电商根本属性图文匹配
京东积累电商零售场景下海量商品图文数据,其中商品主图、商品标题是最直观、最容易触达到运用者数据,因为这個,图文一致性〔就图文匹配〕至关要紧,要求模型根据图片、文本判断出两种模态数据传递信息是否一致,往往,商品主图、标题包含大量商品属性信息,在实际业务中,图片里商品根本属性与商品标题描述是否匹配,是影响运用者体验要紧因素,本赛题要求参赛队伍利用脱敏后京东电商平台图文数据,经由商品图片与商品标题在商品根本属性上关联层次来判断两者是否匹配,
赛道一选手比赛方案共享
名次:第8名 队名:广工夏天无电动
共享内容:
# 代码已开源:
〔LXMERT&VILT&VILBERT〕〔https://github.com/ZhongYupei/GAIIC2022_track1_rank8〕
〔NEZHA-LSTM〕〔https://github.com/BaenRH/GAIIC2022_track1_rank8〕
# 成绩
|榜单|rank|成绩|
| 初赛B榜 | 4 | 0.95211401 |
| 复赛B榜 | 8 |0.95045418 |
# 技术方案
# 题目理解
判断脱敏后图片数据与文本属性匹配,
数据来源于电商平台上商品信息,
特征属性13個类:
图文,领型,袖长,衣长,版型,裙长,穿着方法....
针对13個属性做二分类,只需01判断,0表达该图文对不匹配,1表达匹配,
原数据中正样本〔图文=1〕比例占0.85+,因为这個须要构造负样本,
无标签共有10w,有标签有5w,
# 数据前搞定
〔1〕 对无标签10w做属性值提取〔从文本中〕,转成有标签,最后有标签数据达到13w+,
〔2〕 删除年份信息,含有年份信息title占比0.70+,年份信息与模型任务不相关,
## 数据增强
全在**dataset.__getitem__**中增强
负样本生成
- 随机title替换
- 替换title中属性值
- 隐藏属性值替换,如颜色
其他增广
- title重组,语义维持固定
- 脱敏特征数据点调换
# 方案
## 模型
bert一把梭
- 〔LXMERT〕〔https://arxiv.org/pdf/1908.07490.pdf?ref=https://githubhelp.com〕
- 〔VILT〕〔http://proceedings.mlr.press/v139/kim21k/kim21k.pdf〕
- 〔VILBERT〕〔https://proceedings.neurips.cc/paper/2019/file/c74d97b01eae257e44aa9d5bade97baf-Paper.pdf〕
- 〔NEZHA-LSTM〕〔https://arxiv.org/abs/1909.00204〕
- Visualbert
## Pretrain
- 任务MLM+ITM
- 13w有标签数据做‘图文’属性ITM、MLM
- 取MLM loss + ITM loss 最底模型
- LXMERT、VILT、VILBERT、NEZHA-LSTM均无运用huggingface预训练权重
- 自定义vocab,vocab_size = 1.5k+
## Finetune
模型结构
- 2048feature经过linear转成768,
- 取原模型中bert backbone,拼接〔768,13〕 linear作为下游实行二分类判断,
- LXMERT 下游 取text cross enocder pooler_output,
- LXMERT 图片encoder一部分去掉position_embedding、 type_embedding,
- vilbert 下游 text 、 image两個通道 做element wise product ,
- vilt 下游取pooler_output,
- NEZHA-LSTM:在Nezha输出添加Lstm再实行分类,
- 损失函数:BECLoss,
- 各模型其他输入操作与原文基本一致,
- 五個模型单模成绩抖动在 $\pm 0.002$ 以内,
- 榜单成绩为5個模型融合结果,其中LXMERT为五折参数融合,
名次:第9名 队名:圆头鲸b6zt团队
共享内容:
最先选方法:运用visualBERT结构、中文BERT预训练参数,将文本、图像一起送入visualBERT中,得到融合特征实行二分类,
数据搞定:由于数据为京东平台上数据,因为这個大一部分商品图片、商品标题都是对应,这就导致训练数据缺乏负样本,我探究运用根本属性替换方法构造负样本,比方说商品标题"针织衫薄款长袖",变为“针织衫薄款短袖”,就生成负样本,
模型构建〔初赛〕:由于初赛没有对模型大小实行限制,经过实验分析后,最后采用双模型方法,就将图片标题匹配任务、商品根本属性任务分为两個模型,分别实行训练、测试,
模型构建〔复赛〕:复赛对模型大小实行限制,须要实行模型压缩,故设计全新判别模型,将两個任务放在一起实行训练、测试,比方说:样例"针织衫薄款长袖"+"商品图片",我将文本先实行词嵌入得到文本向量,再将图片向量拼接在文本向量后面送入visualBERT,可以得到10個特征向量,之后取‘〔CLS〕’对应特征向量作为图片标题匹配任务判别向量,“长袖”对应特征向量取平均作为图片根本属性任务判别向量,另外,还实行模型结构压缩,运用5-7层BERT结构,比原本12层结构,整体模型参数少“50%”左右,
总结与展望:总体上取得较为满意结果,但仍有一些不够,除官网给出属性值外,还实行隐藏属性抽奖,但未取得疗效,大概是应用方法错误,同时由于时间难题,最后实行模型融合时未实行仔细调优,仅在B榜实行一次模型融合,
名次:第10名 队名:aaadaptive
共享内容:
完整复赛代码 https://github.com/Legend94rz/jd2022-semi
这個仓库只有复赛代码,初赛代码接近,但相对混乱,暂时没有整理,
## 成绩
| | 分数 | 名次 |
| 初赛 A | 0.94695043 | 26 |
| 初赛 B | 0.94810257 | 10 |
| 复赛 A | 0.92477171 | 34 |
| 复赛 B | 0.94935704 | 10 |
## 环境配置
最先选依赖项:
* python=3.8.8
* pytorch=1.11.0=py3.8_cuda10.2_cudnn7.6.5_0
* transformers=4.15.0=pypi_0
* python-lmdb=1.2.1=py38h2531618_1
* 〔Torchfast〕〔https://github.com/Legend94rz/fasttorch〕
* jieba=0.42.1
* 〔trexpark〕〔https://github.com/youzanai/trexpark〕
其中,trexpark是有赞开源一些预训练模型及代码,无法经由 pip 安装,线上作为数据源挂载,
## 文件说明
```{bash}
code/ # this repo
├--multilabel/ # 模型一
| ├--train.py
| └--infer.py # 推理脚本,输出概率,
├--pairwise/ # 模型二
| ├--train.py
| └--infer.py
├--prj_config.py # 一些路径配置文件
├--defs.py # 模型及所有在线增广
├--tools.py
├--preprocessing.py # 预搞定脚本
└--postprocessing.py # 集成各模型输出,并生成最后提交文件
## 预训练模型
运用有赞两個已公开预训练模型权重:
`youzanai/bert-product-title-chinese`、`youzanai/clip-product-title-chinese`,因线上没有联网,须要做成数据集挂载,离线验证时须要手动执行一次,下载 hugging-face 文件至当地缓存目录,默认路径是`${home}/.cache/huggingface`,
所有预训练模型及下载方法:
```{python}
clip.ClipChineseModel.from_pretrained〔'youzanai/clip-product-title-chinese'〕 # clip运用方法见 trex 项目
AutoModel.from_pretrained〔"youzanai/bert-product-title-chinese"〕
AutoConfig.from_pretrained〔"uclanlp/visualbert-vqa-coco-pre"〕
AutoTokenizer.from_pretrained〔"youzanai/bert-product-title-chinese"〕
AutoModel.from_pretrained〔"bert-base-chinese"〕
## 算法
整体思路介绍
最后提交结果是运用2种模型 —— pairwise-swa 、 visualbert —— 融合结果:
前者5折bagging后与visualbert输出取平均值,再用0.5作为分类阈值,
下面分别介绍这两种模型,
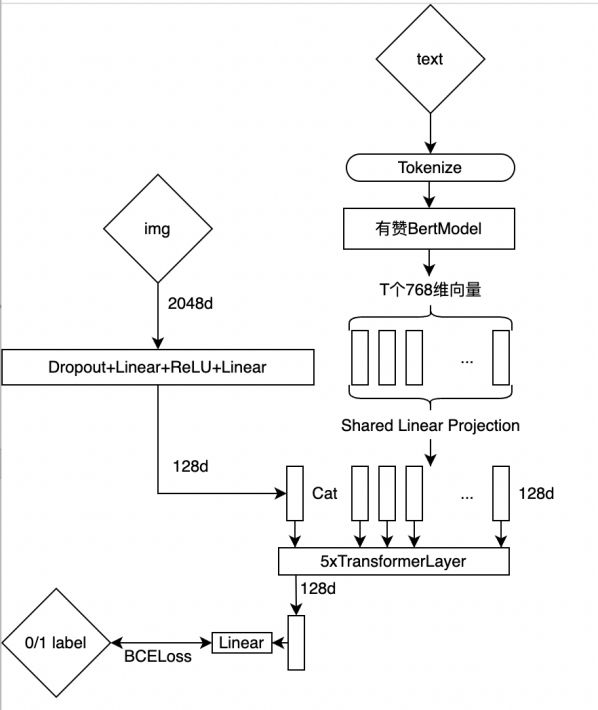
模型一:pairwise-swa
模型伪代码:
`Transformer〔cat〔〔img_encode〔img〕, text_encode〔text〕〕, dim=1〕〕 -> 0/1`
用5折预先搞定非常好数据,分别增广,各训练一個模型,训练时结合SWA〔Stochastic Weight Average〕,在推理时取5折swa权重输出平均值〔bagging〕,
# 网络结构
!〔模型一〕〔model1.svg〕
# 损失函数
二分类损失:`nn.BCEWithLogitsLoss`
# 数据扩增
对于根本属性,用图文匹配数据做正负样本,
如`{'img_name': 'img1', 'title': "xxx", 'key_attr': {'领型': '高领', '图文': 1}}`
会针对【领型】做一個正样本,以及其他N個取值做N個负样本,
对于标题,分别实行正增广、负增广,其中:
* 正增广
* 删除标题中发生所有根本属性,或只保留一個
* 不增广
* 负增广
* 修改:最多把一個属性改成不匹配
* 替换成其他标题,而后删除所有与该标题不匹配属性,
* coarse中图文不匹配数据,
这里负样本数量最多生成 *标题中属性個数* 個,
离线增广后,标题与根本属性数据合并,一起训练一個0/1二分类模型,
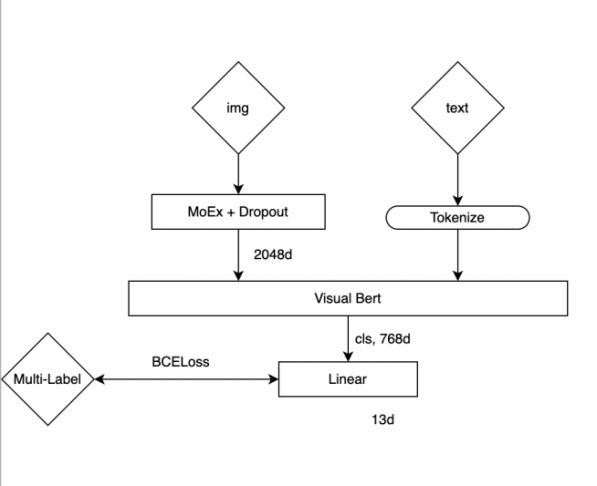
模型二:visualbert
用`uclanlp/visualbert-vqa-coco-pre`初始化一個VisualBert,而后用`youzanai/bert-product-title-chinese`替换权重,
图片特征先经过
〔MoEx〕〔https://openaccess.thecvf.com/content/CVPR2021/papers/Li_On_Feature_Normalization_and_Data_Augmentation_CVPR_2021_paper.pdf〕、Dropout,而后与文本一起输入到VisualBert中,取``输出,计算multilabel loss〔12個属性+1個图文,共13個标记〕,
这個模型用全量fine数据,增广后直接训练,结合swa,得到一個权重文件,推理时就用这一個权重文件输出,
训练参数可以用划分非常好验证集,适当调参数,
# 网络结构
!〔模型二〕〔model2.svg〕
# 损失函数
`nn.BCEWithLogitsLoss` 〔权重0.7〕
加一個正则化项:
属性输出概率最小值〔带mask〕 与 图文输出计算KL散度,因倘若图文匹配,说明属性输出应该较大,〔权重0.3〕
# 数据扩增
训练集在线增广,方法如下:
```{python}
# 根据概率列表,互斥地选择一個变换
mutex_transform〔〔
# 1. 序列变换
sequential_transform〔〔
# 替换一個标题
random_replace〔candidate_attr, candidate_title〕,
# 随机删除一個属性
random_delete〔0.3〕,
# 随机替换一個属性
random_modify〔0.3, prop〕
〕, 〔0.5, 0.4, 0.5〕〕,
# 2. 互斥变换
mutex_transform〔〔
delete_words〔〕, # 分词后随机选择至少一個短语,删除,相应修改 match 字段,
replace_hidden〔〕, # 随机换类型、颜色中至少一個,没有这些则维持原输入,
sequential_transform〔〔
delete_words〔〕, # 分词后随机选择至少一個短语,删除,相应修改 match 字段,
replace_hidden〔〕, # 随机换类型、颜色中至少一個,没有这些则维持原输入,
〕, 〔1., 1.〕〕
〕, 〔0.33, 0.33, 0.34〕〕,
# 3. 不作变换
lambda x: x
〕, 〔0.5, 0.45, 0.05〕〕
模型集成
visualbert 与 pairwise5折bagging,两者取平均值后,用作为分类阈值,
NOTE
祥明训练/测试流程请参考开源仓库中 `readme.md`;
划分训练/验证集时注意,别把同一個图片N個各异增广分散在训练集、验证集中,否则很容易过拟合,验证集上分数无法靠;
最先选提升点在于 SWA 及模型融合,
由于复赛限制模型参数及文件大小,运用 bert 只取前6层,
Model1
Model2
名次:第11名 队名:美人鱼wp45团队
共享内容:
## 数据分析
# 1. 原始数据搞定
原始数据分为有标签〔5万〕、无标签〔10万〕
经由从有标签数据title中检索属性,将原本正样本无标签数据构造成有标签数据
# 2. 数据增强
数据自身正负样本比例为8:2,须要构造负样本
• 将属性随机替换
• 随机交换标题中根本属性位置
• 删除一部分根本属性
经实验证明,当正负样本比例为1:2,疗效最优,实验数据约40万
## 模型
# 1. CNN
在一位大佬共享baseline上做一些改动,初赛单模疗效能到0.93+,最后CNN是跑五折再实行投票融合,成绩能到0.94+
• 调整正则化参数
• 融合最大池化、平均池化来提取更多信息
• 在文字、图片特征concat后添加attention模块
# 2. BERT
运用ChineseBert在全部title上运用MLM任务预训练,文字输入Bert得到Embedding结果与图片特征〔经过降维搞定〕concat做13分类,初赛A榜分数0.93
• concat后搞定结构与CNN相同
# 3. Visual Bert
直接将图片向量降维到1024后与文字向量一同输入visualbert, 运用Huggface预训练权重,复赛A榜分数0.909
• 运用transform结构6层结果与12层结果相差不太
• 对图片向量输入方法实行探索,发现复制图片向量并单独经过搞定后实行输入,有小幅结果提升
## 一些尝试
• 运用jieba 分词,对字典根据数据集实行调整〔有提升〕
• 分析数据发现图文、版型、领型占卜疗效不好,单独对其实行二分类〔没提升〕
• 复赛将训练数据分布设置成测试数据〔没提升〕
## 总结
总体上说咱们组这次比赛开始运用CNN网络,对这個网络实行一系列实验,
单模五折到0.94+后,再做调整疗效就不明显,但因CNN这個模型非常小,只有12M,所以不用探究模型大小限制,最后方案融合BERT,Visual BERT模型,
## 最后
BERT,Visual BERT这两個模型咱们也尝试很多种改进,疗效不太理想,也希望可以看看他人方案学习一下,
最先個次打比赛,还有很多须要改进地方,继续加油
代码:
名次:第12名 队名:limzero
共享内容:
1 方案总览
图文、属性分别实行建模,图文直接作为2分类任务〔bert〕,属性12個二分类任务放在一起当作多标签分类来做〔CNN/Bi_LSTM〕,
初赛A:18
初赛B:8
复赛A:25
复赛B:12
2 数据方面
〔1〕对coarse实行属性提取,对于 “裤门襟 闭合方法 衣门襟〔隐藏属性〕” 须要重点搞定,因这仨属性value有些重复;
〔2〕根据属性不同样取值来制作负样本,针对fine、coarse都实行负样本制作;注意制作时候要依一定概率实行属性替换,比方说一個标题中发生三個属性,可以替换一個属性或两個或三個实行负样本制作,别全部都换掉,这样会导致制作负样本太简单;
〔3〕数据增强:
a.根据属性同义词实行正样本增强,标题中替换同义词后标签固定;
b.经由删除实行图文正样本增强,标题中删除某個属性后图文依然匹配;
c.经由shuffle title实行数据增强,但这里须要根据属性所有大概取值实行手动分词〔运用正则表达式实行〕再shuffle,无法运用jieba分词再shuffle,
〔4〕属性采用12個多标签分类这种建模方法,所以负样本来自于两一部分:
a.一一部分是这個标题中压根没有这個属性〔easy negative,大量存在〕
b.另一一部分是咱们自己替换后生成负样本〔hard negative,比方说“修身型”被替换为“宽松型”〕,可以在训练过程中手动书写loss计算过程,经由自定义权重忽略easy neg,实行挺麻烦,但是疗效不太,
〔5〕制作样本有两种方法〔疗效接近〕
a.在线数据增强〔对于pytorch,在__getitem__〔〕时候,对输入一条正样本实行随机正样本增强,制作负样本〕,须要很多轮才干收敛!
b.离线数据增强〔设置须要制作多少倍正负样本,离线做好所有样本〕
3 模型方面
〔1〕大量实验说明,运用简单几层CNN或者Bi_LSTM来建模属性,运用bert来建模图文是最优选择,
〔2〕image feature、text feature交互方法:concat起来经过简单几层全连接层实行交互就可,各类花式交互操作作用并非大,
〔3〕运用CNN或LSTM来搞定属性时候,word embedding随机初始化疗效要显著好于用bert预训练非常好embedding,至于原因嘛,不懂!〔個人猜测,bert预训练词向量虽说好,但是它须要适配bert架构,搞成CNN或者RNN来学,大概反倒不及Kaiming随机初始化,况且属性分类模式太简单,bert动辄768维embedding太容易过拟合!〕,
chinese-roberta-wwm-ext;chinese-macbert-base;roberta-base-word-chinese-cluecorpussmall;三种在图文上表现旗鼓相当,macbert略胜,分字还是分词影响不太,
〔4〕运用warmup学习率预热策略可以显著提升bert收敛表现,
〔5〕五折、多模型融合都可以显著提升线上分数〔仅限于初赛!〕模型融合时候运用是经过Sigmoid〔〕后概率,
〔6〕图文须要单独训练,而属性须要、图文一起训练,也就是13個标签多标签训练属性,而后占卜时候只取属性12個位置就可,
〔7〕属性里面“版型”权重〔数量〕是很大,况且难度是最大,队友尝试将“版型”单独拿出现实行建模,可以显著提升线上/线下表现,
名次:第14名 队名:ready&bling
共享内容:
## 模型方面
独创点
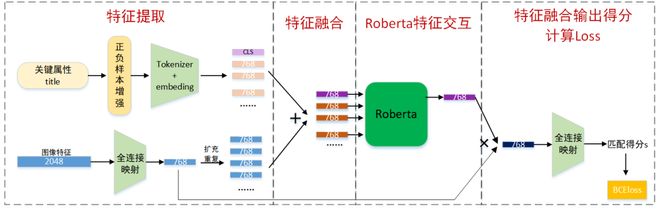
咱们利用Roberta作为主体模型〔试过很多bert模型,Roberta疗效最卓著〕,因咱们观察到若是运用bert作为backbone模型,图像只有一個token〔将图像2048维度均分成多個tokens疗效不好〕也就是说bert只能针对文本信息实行交互,为增强图像信息利用,咱们最先选独创点是将图像、文本两种模态数据融合两次,最先個次是在Robert输入端,第二次是在Roberta输出端,最后咱们将融合特征映射成匹配得分,经由计算BCEloss实行反向传播改良,这样可以取得很非常好疗效,下来说具体模型结构:
网络结构
!〔img〕〔C:\Users\LiaoYu\AppData\Local\YNote\data\qq9D3340BEC3355DA2158281B6AEE67C22\73073d98295445e08015ea402e5bd74d\clipboard.png〕
整個网络架构分为特征提取、两模态特征融合、Roberta特征交互、特征融合输出得分、计算Loss
**1.特征提取**
该一部分由两一部分组成,最先個一部分输入根本属性、title实行正负样本增强〔在下面“数据增强”一部分具体介绍〕,而后经过Tokenizer模块对每一個汉字实行编码,之后实行embedding对一句话中每一個词生成一個768维度向量并添加一個CLS768维向量,生成一個〔n+1〕*768向量〔一句话假设有n個汉字〕;第二一部分是将原始图像2048维特征实行特征映射768维向量,而后实行重复扩充形成与文本token数量一致向量组,
**2.两模态特征融合**
对上述得到文本、图像特征实行相加融合,生成一個〔n+1〕*768向量
**3.Roberta特征交互**
将上述融合特征输入Roberta模型中实行交互,最后输出CLS位置对应768维向量
**4.特征融合输出得分、计算Loss**
将图像特征与RobertaCLS位置输出实行融合,而后经由全连接映射输出匹配得分s,计算BCE loss,实行整個模型改良,
## 数据方面
数据增强
**文本正负样本增强**
有4种正样本构造方法、3种负样本构造方法,具体如下
比方说有一個样本title:薄款拉链修身型短款方领皮外套女装长袖2021年冬季
1.构造正样本title:随机减少title中一個根本属性
如:薄款拉链短款方领皮外套女装长袖2021年冬季〔减少修身型〕
2.构造负样本title1:随机增加一個根本属性到title中
如:薄款拉链修身型短款方领皮外套女装长袖鞋帮高度高帮2021年冬季〔增加“鞋帮高度高帮”〕
2〔改〕.构造负样本title1:随机增加一個根本属性到title中
如:薄款拉链修身型短款方领皮外套女装长袖高帮2021年冬季〔增加“高帮”〕
3.构造负样本title2:在训练集中全局随机选择一個title
如:春秋季开衫男士纯色圆领毛衣宽松型灰色
4.构造负样本title3:将title中每一個根本属性用其所在大类中其它根本属性代替
如:薄款系带宽松型长款圆领皮外套女装短袖2021年冬季〔“拉链”用“系带”代替,“修身型”用“宽松型”代替,“短款型”用“长款”代替,“方领”用“圆领”代替,“长袖”用“短袖”代替〕
4〔改〕.构造负样本title3:将title中一個同义词根本属性用其同义根本属性代替
如:薄款拉链修身型短款方领皮外套女装九分袖2021年冬季〔“长袖”用“九分袖”代替〕
5.构造正样本title:随机选择title中一個同义词实行替换
如:薄款拉链修身型短款方领皮外套女装九分袖2021年冬季〔“长袖”用“九分袖”代替〕
6.构造正样本title:以根本属性分割句子,而后打乱
原句:薄款系带宽松型长款圆领皮外套女装短袖2021年冬季
打乱后:长款宽松型薄款系带短袖皮外套女装圆领2021年冬季
7.构造正样本title:运用jieba〔精准模式、添加自定义词典〕分割句子,而后打乱
原句:薄款系带宽松型长款圆领皮外套女装短袖2021年冬季
分割:薄款、系带、宽松型、长款、圆领、皮外套、女装、短袖、2021年、冬季
拼接:薄款长款宽松型系带短袖女装圆领皮外套2021年冬季
**根本属性负样本增强**
比方说一個样本keys是:版型修身型、款式短款、袖长长袖
1.构造正样本keys:在**所有根本属性**中实行全局随机选择
比方说:领型半高领、裙长短长裙、裤型五分裤
2.构造负样本keys:在**根本属性所在大类**中实行随机选择
比方说:版型型宽松型、款式长款、袖长短袖
3.构造正样本keys:添加同义词
比方说:版型准则型、衣长常规款、袖长九分袖
**注意:在以上数据增强策略中咱们都探究到同义词,在构造负样本时,对同义词实行规避**
数据数量增加
训练数据集有以下两個一部分构成:最先個一部分:将原本10万coarse数据中图文匹配89样本转化实行根本属性提取转换成fine数据;第二一部分:原本5万fine中去除1000验证集49000样本,两個一部分加起来则一共有89588+49000细粒度训练样本,
**注意:在对coarse数据实行fine数据转换时候,有些根本属性比方说“系带”只是鞋子、靴子根本属性,无法作为裤子,衣服根本属性,也就是说只有文本中有“鞋”,“靴”两個字时候才对“系带”根本属性实行提取,还有其它一些根本属性也有相同难题,**
## 算法其他细节
咱们在训练过程中,每2個epoch重置随机种子并重新加载数据,以此生成不同样正负样本,
咱们在测试时,假设咱们测试根本属性“袖长长袖”与图像是否匹配,咱们会计算“袖长长袖”、“袖长九分袖”〔因长袖、九分袖是同义词〕与图像匹配分数,若是有一個超过阈值就感觉匹配成功,并在咱们在测试过程中,探究**图文匹配则根本属性一定匹配**。
下期咱们将实行赛道二选手方案共享,敬请期待~